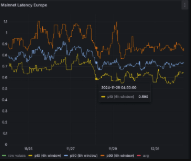
Consensus latency measures the time from a request to a final, agreed outcome across nodes. It reflects network delays, processing time, and coordination overhead. Real systems show variability due to queueing, leadership changes, and view changes. Different consensus algorithms trade safety for speed via quorum rules and proposer counts. Measurement and modeling help identify bottlenecks and mitigation strategies. The topic invites practical examination of tuning, reconfiguration, and adaptive timeouts to sustain throughput under real-world conditions.
What Is Consensus Latency and Why It Matters
economic impact, privacy concerns
Where Latency Comes From in Real-World Systems
Latency in real-world systems arises from a combination of network, processing, and coordination delays.
Real-world latency stems from jitter sources and network variance, layered with protocol overhead and queueing effects.
Processing delays reflect CPU, storage I/O, and context switches.
Coordination overhead includes consensus handshake, leadership changes, and commit messaging.
The result is a spectrum of delays, not a single fixed value.
How Different Consensus Algorithms Trade Safety for Speed
Consensus algorithms navigate a trade-off between safety guarantees and time to progress. Different designs optimize for speed with looser safety assumptions or strengthen safety at the cost of latency. Practical variants adjust upgrade tradeoffs, balancing view changes, proposer counts, and message complexity. Fault tolerance scales with quorum requirements, impacting resilience and performance under partitions, failures, and adversarial conditions.
Practical Measurement, Modeling, and Mitigation Techniques
Network partitioning insights guide adaptive timeout strategies, reconfiguration, and quorum adjustments, enabling sustained throughput while preserving consistency guarantees across diverse, freedom-seeking deployments.
See also: AI in Healthcare Transformation
Frequently Asked Questions
How Does Network Jitter Affect Consensus Timing in Practice?
Network jitter introduces latency variance, slowing and staggering message rounds; practical effects show jitter propagation amplifying consensus timing, increasing commit latency and timeout risk. The system tolerates some fluctuation, but increases practical variability in decision points.
Can Latency Differences Impact Transaction Ordering Guarantees?
Latency differences can affect transaction ordering guarantees, challenging latency fairness, and potentially reordering decisions. Parallelism yields resilience, reducing sensitivity to delays; careful synchronization and deterministic timing preserve ordering guarantees while embracing freedom in networked environments.
What Role Do Clock Synchronization Errors Play?
Clock drift and timing skew introduce misalignment among nodes, complicating consensus. They cause non-deterministic ordering and forks; mitigation relies on tighter synchronization, robust timeout policies, and cross-node clock correction to preserve safety without sacrificing liveness.
Do Legal or Regulatory Factors Influence Measurable Latency?
A notable stat shows 99th percentile latency variability; legal or regulatory factors do influence measurable latency. In practice, legal compliance and regulatory reporting requirements can introduce scheduling and auditing delays, affecting observable consensus latency, albeit transparently under governance policies.
How Do Hardware Failures Skew Latency Benchmarks?
Hardware failures introduce benchmark skew by disrupting network jitter and clock synchronization, skewing latency measurements and consensus timing; robust measurement requires isolating nodes, repeating trials, and documenting variance to prevent misinterpretation of overall performance.
Conclusion
Consensus latency is the elapsed time from a request to a final, agreed decision, shaped by network, processing, and coordination delays. In practice, latency arises from message delays, leadership changes, and quorum waits, with variance driven by load and topology. Different algorithms trade safety for speed via view changes and quorum structures. Measurement and mitigation—adaptive timeouts, reconfiguration, and tuning—are essential. Example: a blockchain-like BFT system exhibits higher latency during view changes; dynamic reconfiguration can restore throughput while preserving safety.